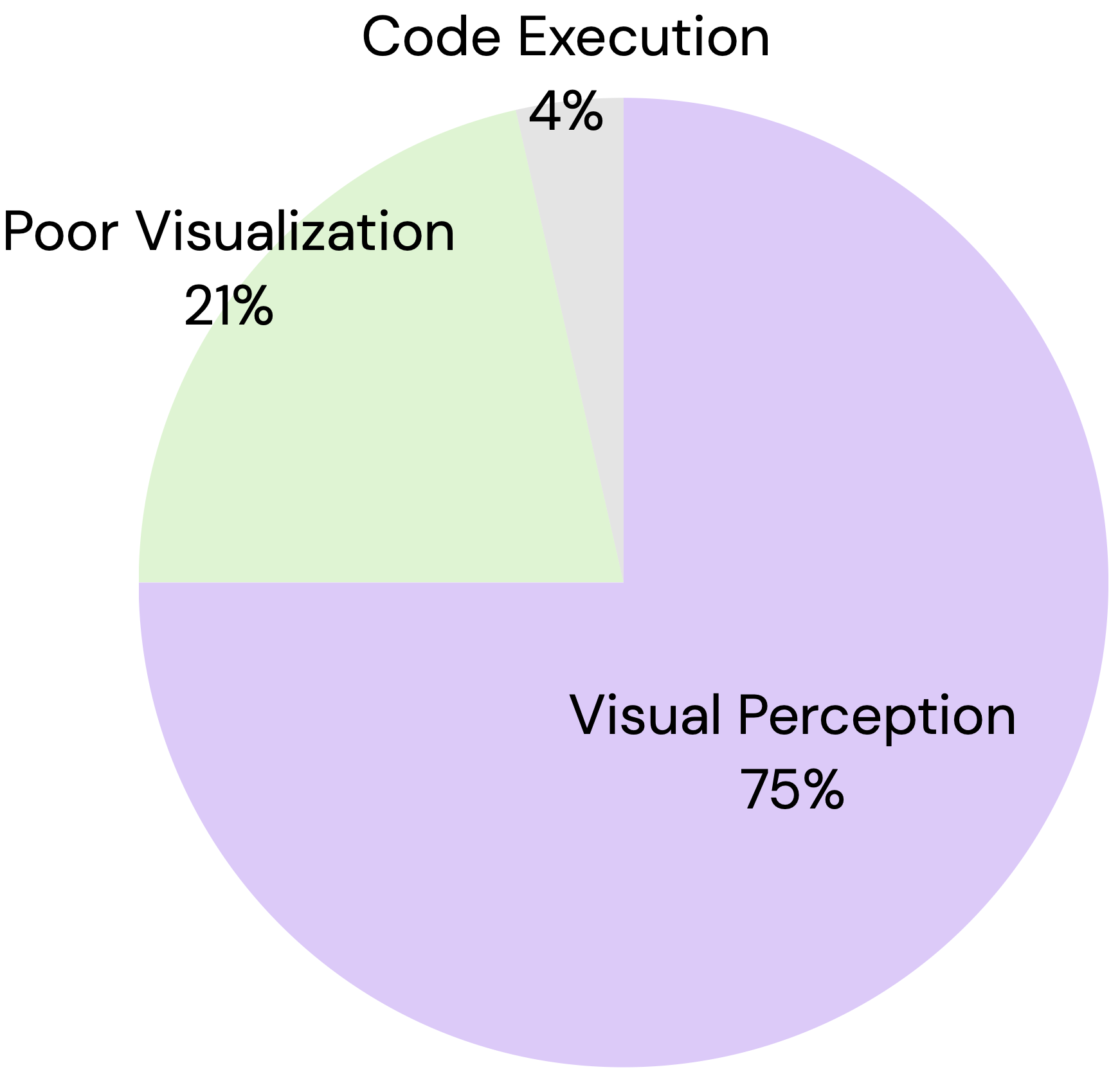
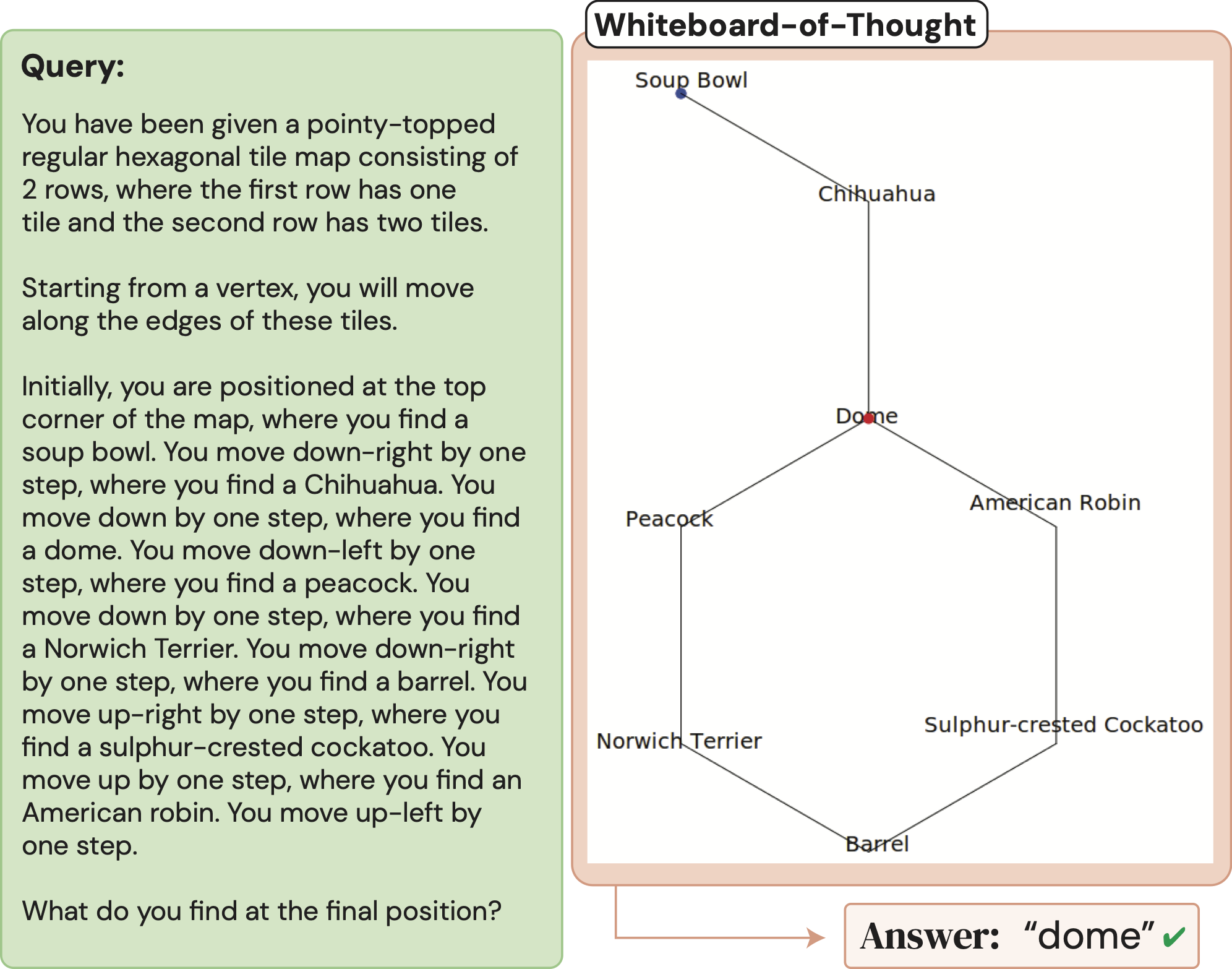
Evaluation: ASCII Understanding
ASCII understanding is a clearly visual task with only text inputs. For humans, written text is typically processed with the same input modality as images (our eyes), allowing us to engage in visual thinking without any intermediate processing.

Examples of three BIG-Bench ASCII understanding tasks + WoT visualizations.
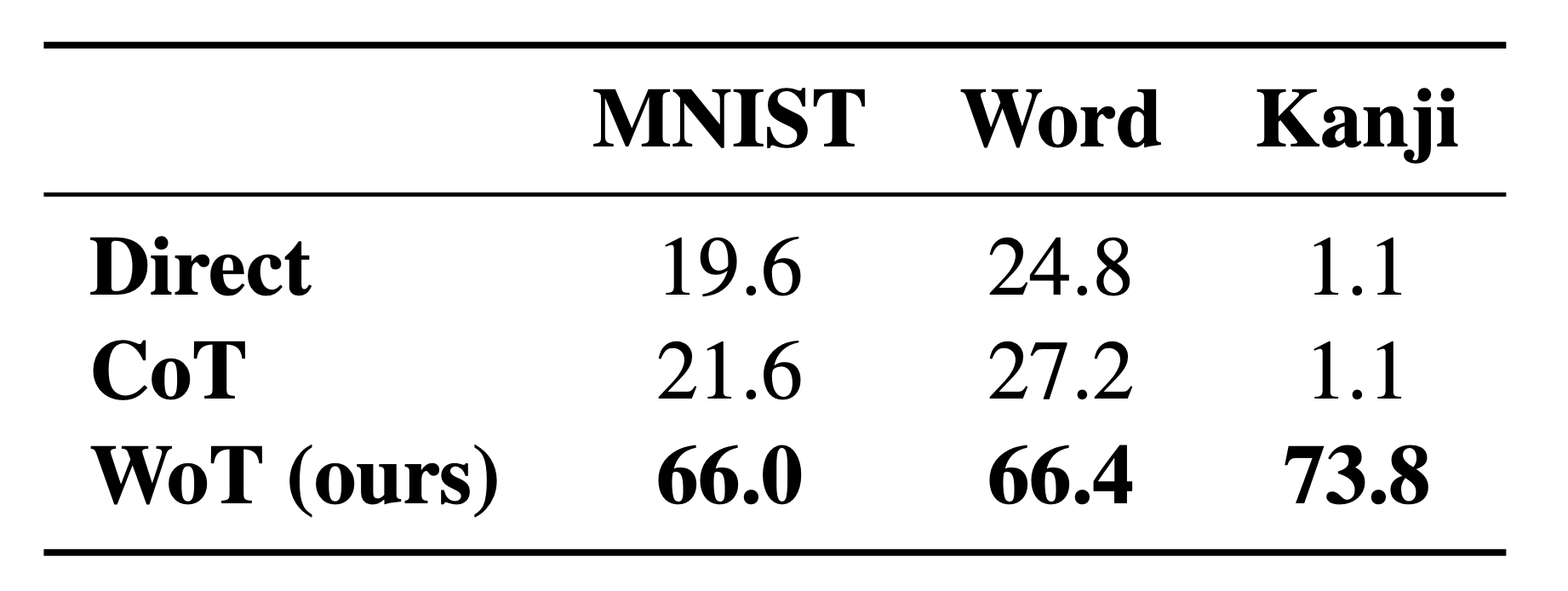
ASCII accuracy. MLLMs fail to perform the task with text alone. WoT unlocks visual processing to achieve substantial gains.
Consider the difficulty of understanding ASCII art being read aloud. In some sense, this is similar to how LLMs process ASCII.

Breaking down the ASCII word recognition performance, we see 'Bubble' and 'Doh' can be solved without visuals.
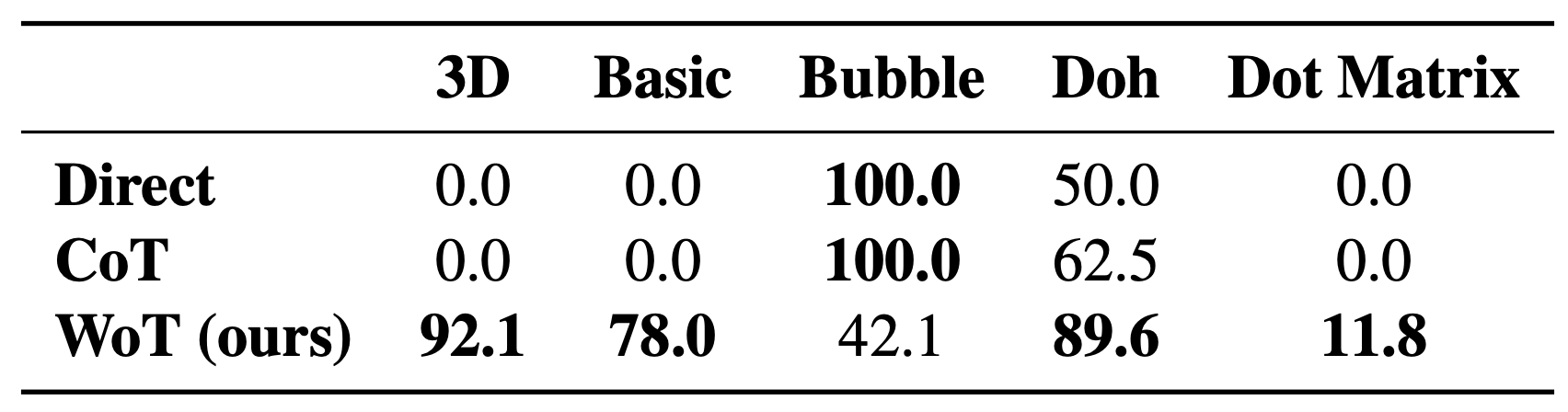
Text-only baselines fail to solve every instance that actually requires visual understanding.